

Uvod
Čak je i Google zvanično objavio da toleriše nekoliko istih sajtova. To jest možete imati nekoliko istih web sajtova i zadržaće te poziciju u njihovom pretraživaču. Drugo, svet je pun plagijata i to je sasvim normalno. Isto kako ljudi prenose informacije jedni preko drugih (i viruse), tako i sajtovi prenose iste.
Sada se postavlja pitanje, kako skinuti određene detalje sa nekog web sajta da bi iste postavili na drugi?
Priprema i pisanje koda za skidanje detalja sa web stranica
Za ovaj tutorijal koristi ću Python jer je jednostavan i lak za primenu. Moje radno okruženje je Windows 10, a Python skriptove otvaram u Visual Studio Code. Takođe koristim i geckodriver za upravljanje Firefox web browser-om.
Potrebno je prvo da instalirate Python, dodate putanju do bin foldera u Path i restartujete računar. Napravite jedan folder koji možete nazvati kako god hoćete. Pokrenete VS Code i otvorite taj folder u njemu. Dodate start.py datoteku u njemu i kliknete dole levo na status bar da izaberete aktuelnu instalaciju Python-a. Takodje VS Code će Vam ponuditi da instalira preporučene dodatke, Vi to uradite, trebaće Vam (ms-python.python).
Sajt čije detalje ćemo da skidamo je https://stackoverflow.com/jobs . Kopirajte geckodriver.exe u isti folder gde ste napravili start.py. Dodajte u zaglavlje sledeće import direktive:
from selenium import webdriver import time, random
import direktiva omogućuje Python-u da koristi neke već napravljene biblioteke klasa koje olakšavaju programerski posao (što čete videti u ovom primeru najbolje). Međutim neke od ovih biblioteka ne stižu sa instalacijom Python-a, već ih je potrebno dodatno instalirati. Da ne bi Vi sada petljali i tražili te biblioteke na internetu, za to postoji pip program. Otvorite komandnu liniju i kucajte pip install selenium da bi ste instalirali selenium biblioteku, to isto uradite i sa svim ostalim bibliotekama koje nemate na Vašem računaru.
wait_from = 4 wait_to = 8
Ove dve varijable će definisati opseg u sekundama koje će skript da čeka po otvaranju stranice. Ne želimo da učitavamo stranice suviše brzo jer je moguće da je sajt konfigurisan da nas blokira u suprotnom.
browser = webdriver.Firefox()
browser.get("https://stackoverflow.com/jobs")
Ovde smo definisali da želimo da upravljamo sa Firefox-om i otvaramo ovu stranicu prvo. Kada se stranica otvori izgledaće ovako:
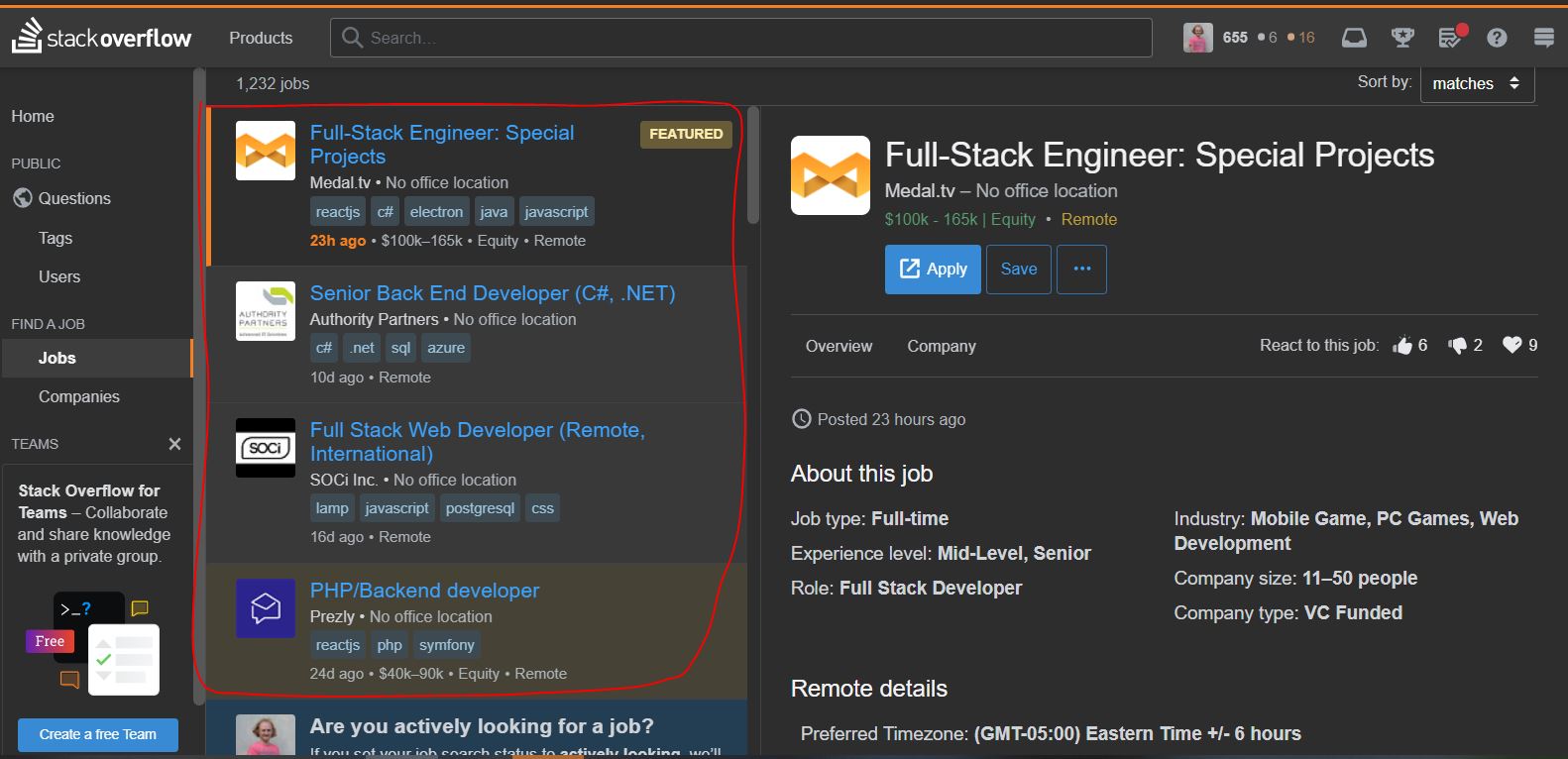
Cilj nam je skinuti naslov svakog posla, međutim tu postoji nekoliko stranica. Cilj nam je kretati se kroz te stranice i skidati poslove sve do poslednje stranice.
with open("stackoverflow-jobs.txt", "w") as txt_file:
txt_file.write("stackoverflow jobs\n")
txt_file.flush()
Sledeće što ćemo uraditi jeste otvoriti datoteku gde ćemo ste te poslove da zabeležimo. Posle toga možemo raditi na izvačenju teksta opisa poslova sa te prve stranice koju smo otvorili.
els = []
els = browser.find_elements_by_css_selector('a.stretched-link')
for href in els:
txt_file.write(href.get_attribute("title") + "\n")
browser je aktivan prozor browser-a kojim upravljamo. els je niz elemenata koji popunjavamo pomoću funkcije find_elements_by_css_selector. Ova funkcija uzima css selektor kao parametar. Razmatrenjem izvornog koda, vidim da je idealno ako koristim a.stretched-link selektor. Takođe vidim da je HTML atribut title upravo to što nem treba i beležim to u datoteku. Dalje nam treba sledeća stranica, a do nje ćemo doći klikom na broj 2 u redu za paginaciju i to ovako:
i = 1
found = True
while found:
i += 1
els = []
els = browser.find_elements_by_css_selector('a.s-pagination--item > span')
found = False
for span in els:
if span.text == str(i):
found = True
i nam treba kao brojač strana da uzmemo svaku sledeću stranicu. found ću da koristim da izađem iz beskonačne petlje. Gledajući u izvorni kod stranice vidim da je a.s-pagination--item > span selektor za span u kojem se nalaze brojevi stranica. Vraćam taj niz u els i upoređujem sa stranicom koju očekujem, a kada je nadjem:
browser.execute_script( "arguments[0].parentNode.click();", span)
time.sleep(random.randint(wait_from, wait_to))
els = []
els = browser.find_elements_by_css_selector('a.stretched-link')
for href in els:
txt_file.write(href.get_attribute("title") + "\n")
txt_file.flush()
break
Korstim funkciju execute_script koja će izvršiti JavaScript kod. Ova funkcija takođe prima i parametar u vidu HTML elementa, što je idealno u ovom slučaju. Pozivam click metodu na anchor (parentNode). Zatim čekamo neko vreme da se stranica učita (ovo vreme može da bude veće ili manje u zavisnosti od brzine otvaranja stranice). Dalje ponavljam istu proceduru za izvlačenje teksta kao i pre ove petlje.
Ceo kod:
from selenium import webdriver
import time, random
wait_from = 4
wait_to = 8
browser = webdriver.Firefox()
browser.get("https://stackoverflow.com/jobs")
with open("stackoverflow-jobs.txt", "w") as txt_file:
txt_file.write("stackoverflow jobs\n")
txt_file.flush()
els = []
els = browser.find_elements_by_css_selector('a.stretched-link')
for href in els:
txt_file.write(href.get_attribute("title") + "\n")
i = 1
found = True
while found:
i += 1
els = []
els = browser.find_elements_by_css_selector('a.s-pagination--item > span')
found = False
for span in els:
if span.text == str(i):
found = True
browser.execute_script( "arguments[0].parentNode.click();", span)
time.sleep(random.randint(wait_from, wait_to))
els = []
els = browser.find_elements_by_css_selector('a.stretched-link')
for href in els:
txt_file.write(href.get_attribute("title") + "\n")
txt_file.flush()
break
print ("Done!")
Da li je moguće lako skinuti detalje web stranice?
Danas je moguće vrlo lako programirati i skinuti detalje sa neke veb stranice. U ovom primeru je korišćen Python, ali ovo isto važi i za PHP, C# i druge programske jezike. Nadam se da Vam je ovo kratko uputstvo značilo i molim Vas da ostavite komentar u polju ispod. Hvala na pažnji i odvojenom vremenu!
Ako tražite usluge razvoja softvera najvišeg ranga, ne tražite dalje!
✨ Šta nudim:
- Razvoj veb stranica: Pretvorite vašu ideju u potpuno funkcionalnu veb stranicu.
- Kreacija mobilnih aplikacija: Dostignite vašu publiku na svakom uređaju.
- Prilagođena softverska rešenja: Softver prilagođen vašim poslovnim potrebama.
- Upravljanje bazom podataka: Osigurajte da su vaši podaci strukturirani, sigurni i dostupni.
- Konsultacije: Niste sigurni gde da počnete? Razgovarajmo o najboljim tehnološkim rešenjima za vaše ciljeve.
Sa godinama iskustva u tehničkoj industriji, usavršio sam svoje veštine kako bih pružio samo najbolje svojim klijentima. Pretvorimo vašu viziju u stvarnost. Kontaktirajte me danas da započnemo vaš sledeći digitalni projekat!
Ostavite odgovor