

Увод
Чак је и Гоогле званично објавио да толерише неколико истих сајтова. То јест можете имати неколико истих веб сајтова и задржаће те позицију у њиховом претраживачу. Друго, свет је пун плагијата и то је сасвим нормално. Исто како људи преносе информације једни преко других (и вирусе), тако и сајтови преносе исте.
Сада се поставља питање, како скинути одређене детаље са неког веб сајта да би исте поставили на други?
Припрема и писање кода за скидање детаља са веб страница
За овај туторијал користи ћу Python јер је једноставан и лак за примену. Моје радно окружење је Windows 10, а Python скриптове отварам у Visual Studio Code. Такође користим и geckodriver за управљање Firefox веб browser-ом.
Потребно је прво да инсталирате Python, додате путању до bin фолдера у Path и рестартујете рачунар. Направите један фолдер који можете назвати како год хоћете. Покренете VS Code и отворите тај фолдер у њему. Додате start.py датотеку у њему и кликнете доле лево на статус бар да изаберете актуелну инсталацију Python-а. Такође VS Code ће Вам понудити да инсталира препоручене додатке, Ви то урадите, требаће Вам (ms-python.python).
Сајт чије детаље ћемо да скидамо је https://stackoverflow.com/jobs. Копирајте geckodriver.exe у исти фолдер где сте направили start.py. Додајте у заглавље следеће import директиве:
from selenium import webdriver import time, random
import директива омогућуе Python-у да користи неке већ направљене библиотеке класа које олакшавају програмерски посао (што ћете видети у овом примеру најбоље). Међутим неке од ових библиотека не стижу са инсталацијом Python-а, већ их је потребно додатно инсталирати. Да не би Ви сада петљали и тражили те библиотеке на интернету, за то постоји pip програм. Отворите командну линију и куцајте pip install selenium да би сте инсталирали selenium библиотеку, то исто урадите и са свим осталим библиотекама које немате на Вашем рачунару.
wait_from = 4 wait_to = 8
Ове две варијабле ће дефинисати опсег у секундама које ће скрипт да чека по отварању странице. Не желимо да учитавамо странице сувише брзо јер је могуће да је сајт конфигурисан да нас блокира у супротном.
browser = webdriver.Firefox()
browser.get("https://stackoverflow.com/jobs")
Овде смо дефинисали да желимо да управљамо са Firefox-ом и отварамо ову страницу прво. Када се страница отвори изгледаће овако:
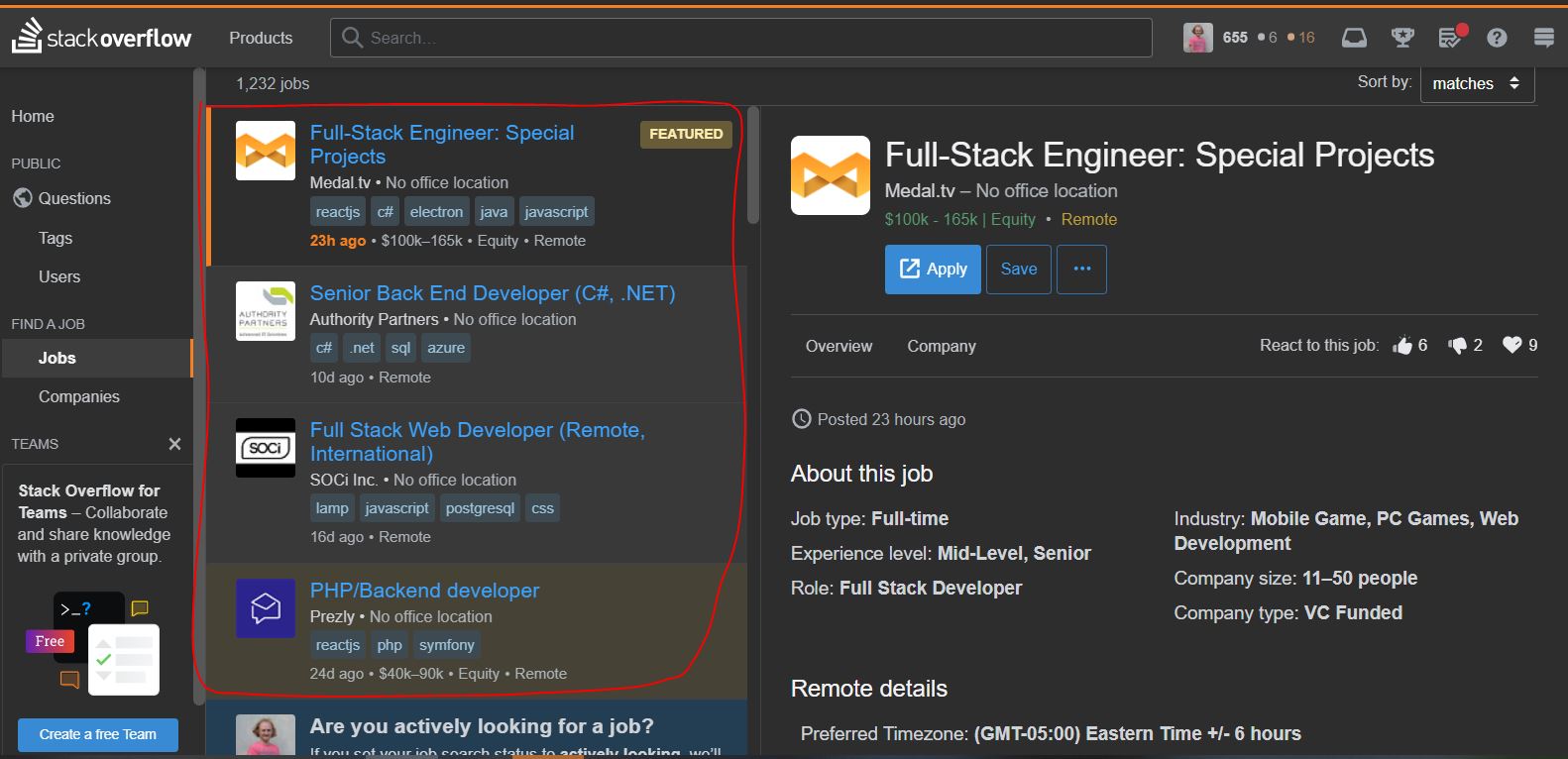
Циљ нам је скинути наслов сваког посла, међутим ту постоји неколико страница. Циљ нам је кретати се кроз те странице и скидати послове све до последње странице.
with open("stackoverflow-jobs.txt", "w") as txt_file:
txt_file.write("stackoverflow jobs\n")
txt_file.flush()
Следеће што ћемо урадити јесте отворити датотеку где ћемо сте те послове да забележимо. После тога можемо радити на извлачењу текста описа послова са те прве странице коју смо отворили.
els = []
els = browser.find_elements_by_css_selector('a.stretched-link')
for href in els:
txt_file.write(href.get_attribute("title") + "\n")
browser је активан прозор browser-а којим управљамо. els је низ елемената који попуњавамо помоћу функције find_elements_by_css_selector. Ова функција узима css селектор као параметар. Разматрањем изворног кода, видим да је идеално ако користим a.stretched-link селектор. Такође видим да је HTML атрибут title управо то што нам треба и бележим то у датотеку. Даље нам треба следећа страница, а до ње ћемо доћи кликом на број 2 у реду за пагинацију и то овако:
i = 1
found = True
while found:
i += 1
els = []
els = browser.find_elements_by_css_selector('a.s-pagination--item > span')
found = False
for span in els:
if span.text == str(i):
found = True
i нам треба као бројач страна да узмемо сваку следећу страницу. found ћу да користим да изађем из бесконачне петље. Гледајући у изворни код странице видим да је a.s-pagination--item > span селектор за span у којем се налазе бројеви страница. Враћам тај низ у els и упоређујем са страницом коју очекујем, а када је нађем:
browser.execute_script( "arguments[0].parentNode.click();", span)
time.sleep(random.randint(wait_from, wait_to))
els = []
els = browser.find_elements_by_css_selector('a.stretched-link')
for href in els:
txt_file.write(href.get_attribute("title") + "\n")
txt_file.flush()
break
Користим функцију execute_script која ће извршити JavaScript код. Ова функција такође прима и параметар у виду HTML елемента, што је идеално у овом случају. Позивам click методу на anchor (parentNode). Затим чекамо неко време да се страница учита (ово време може да буде веће или мање у зависности од брзине отварања странице). Даље понављам исту процедуру за извлачење текста као и пре ове петље.
Цео код:
from selenium import webdriver
import time, random
wait_from = 4
wait_to = 8
browser = webdriver.Firefox()
browser.get("https://stackoverflow.com/jobs")
with open("stackoverflow-jobs.txt", "w") as txt_file:
txt_file.write("stackoverflow jobs\n")
txt_file.flush()
els = []
els = browser.find_elements_by_css_selector('a.stretched-link')
for href in els:
txt_file.write(href.get_attribute("title") + "\n")
i = 1
found = True
while found:
i += 1
els = []
els = browser.find_elements_by_css_selector('a.s-pagination--item > span')
found = False
for span in els:
if span.text == str(i):
found = True
browser.execute_script( "arguments[0].parentNode.click();", span)
time.sleep(random.randint(wait_from, wait_to))
els = []
els = browser.find_elements_by_css_selector('a.stretched-link')
for href in els:
txt_file.write(href.get_attribute("title") + "\n")
txt_file.flush()
break
print ("Done!")
Да ли је могуће лако скинути детаље веб странице?
Данас је могуће врло лако програмирати и скинути детаље са неке веб странице. У овом примеру је коришћен Python, али ово исто важи и за PHP, C# и друге програмске језике. Надам се да Вам је ово кратко упутство значило и молим Вас да оставите коментар у пољу испод. Хвала на пажњи и одвојеном времену!
Ако тражите услуге развоја софтвера највишег ранга, не тражите даље!
✨ Шта нудим:
- Развој веб страница: Претворите вашу идеју у потпуно функционалну веб страницу.
- Креација мобилних апликација: Достигните вашу публику на сваком уређају.
- Прилагођена софтверска решења: Софтвер прилагођен вашим пословним потребама.
- Управљање базом података: Осигурајте да су ваши подаци структурирани, сигурни и доступни.
- Консултације: Нисте сигурни где да почнете? Разговарајмо о најбољим технолошким решењима за ваше циљеве.
Са годинама искуства у техничкој индустрији, усавршио сам своје вештине како бих пружио само најбоље својим клијентима. Претворимо вашу визију у стварност. Контактирајте ме данас да започнемо ваш следећи дигитални пројекат!
Оставите одговор